1. perror / strerror
1) perror
<stdio.h>
void perror(const char *s);- 입력받은 문자열과 errno에 대한 오류 메시지 결합하여 출력
- 오류가 발생하면 해당 오류 코드가 errno에 저장되는데 이를 가져와서 출력하는 것임

2) strerror
<string.h>
char *strerror(int errnum);- 오류 코드를 매개변수로 받아 해당 오류코드에 대한 오류 메시지를 반환
- 문자열을 반환하므로 printf 함수와 함께 사용해야 함

2. access
#include <unistd.h>
int access(const char *path, int mod);- 파일이나 디렉토리에 대한 접근 권한을 확인하는 데 사용
- 접근 권한 확인 후 성공하면 0, 실패하면 -1을 반환
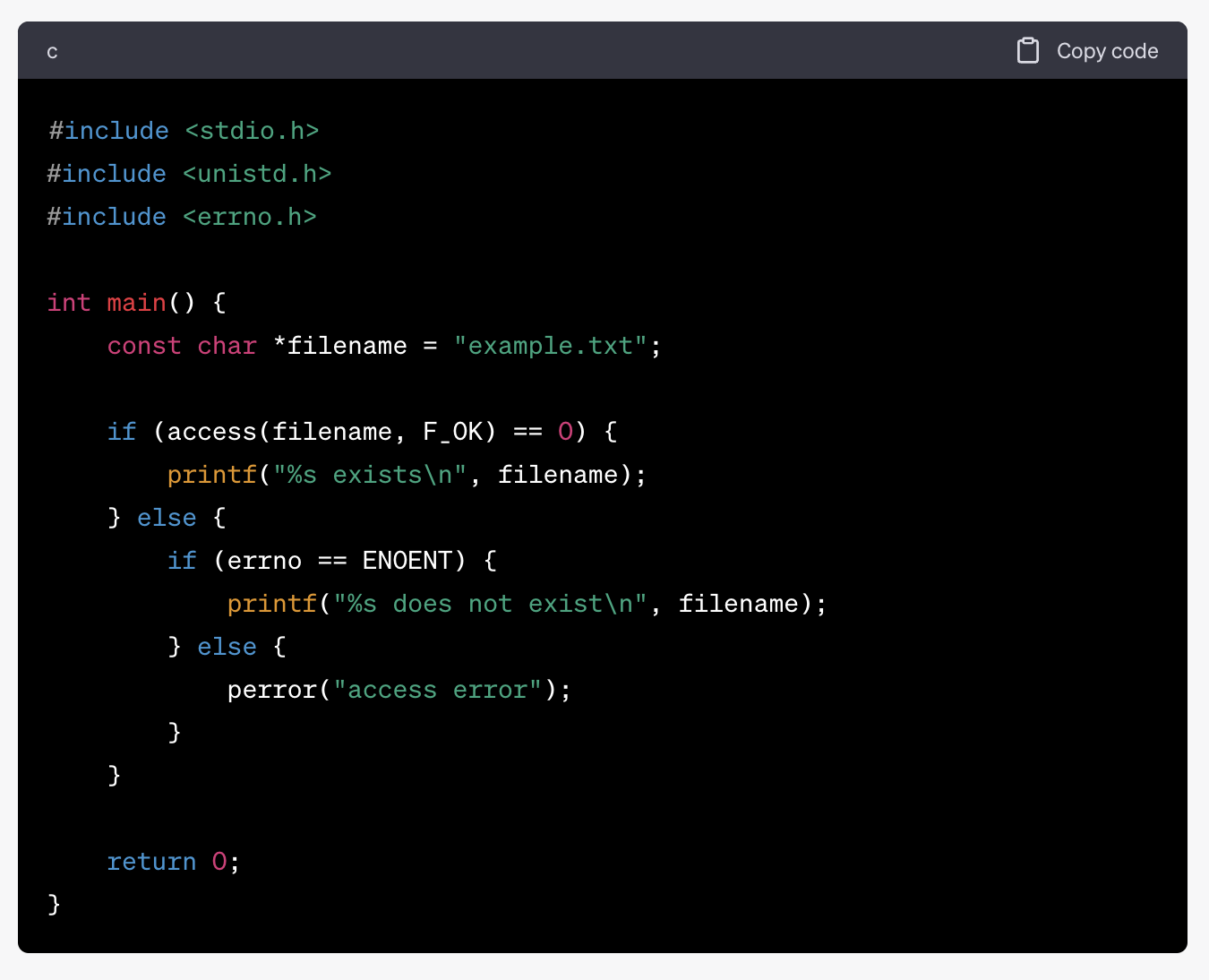
- F_OK : 파일의 존재 여부 확인 / R_OK : 읽기 권한 확인 / W_OK : 쓰기 권한 확인 / X_OK : 실행 권한 확인
3. dup / dup2
int dup(int oldfd);- oldfd로 지정된 파일 디스크립터를 복제하여 새로운 파일 디스크립터를 생성
- 성공시 새로운 파일 디스크립터를 반환하며, 실패시 -1을 반환
#include <unistd.h>
int dup2(int oldfd, int newfd);- oldfd로 지정된 파일 디스크립터를 newfd로 지정된 파일 디스크립터로 복제
- newfd가 이미 열려 있는 경우, new_fd를 닫고 oldfd를 복제하여 newfd로 사용

- 위 경우 표준 출력의 내용이 output.txt에 기록
4. execve
#include <unistd.h>
int execve(const char * pathname, char *const argv[], char *const envp[]);- 지정된 경로 (pathname)의 프로그램 파일을 실행하고, 실행 중인 프로세스의 이미지를 해당 프로그램으로 교체 한 뒤 argv와 envp의 내용을 새로운 프로그램에 전달

5. fork
#include <unistd.h>
pid_t fork(void);- 기존 프로세스에서 새로운 자식 프로세스를 생성 (각 프로세스는 동일한 코드와 상태를 가지지만, 서로 다른 프로세스 ID(PID)를 가짐
- 자식 프로세스인 경우 0을 반환하며, 부모 프로세스인 경우 현재 프로세스가 복제되어 자식 프로세스가 생성

6. pipe
- 파이프는 두 개의 파일 디스크립터로 이루어진 단방향 통신 채널로, 한 쪽에서 쓰여진 데이터를 다른 쪽에서 읽을 수 있게 해 줌
#include <unistd.h>
int pipe(int pipefd[2]);-pipe() 함수는 프로세스 간 통신을 위해 사용되며, 파이프를 통해 데이터를 안전하게 전송
- pipefd[0]은 읽기용 파일 디스크립터를 저장, pipefd[1]은 쓰기용 파일 디스크립터를 저장
-pipe() 함수를 호출하면 파이프가 생성되고, 연결된 파일 디스크립터를 pipefd 배열에 저장
- 파이프는 프로세스간 통신 방법 중 하나로, 파이프는 읽기를 위한 파일 디스크립터와 쓰기를 위한 파일 디스크립터, 총 2개로 이루어짐
- 한 프로세스가 파이프의 쓰기용 파일 디스크립터를 통해 데이터를 파이프에 쓰면 다른 프로세스가 읽기용 파일 디스크립터를 통해 읽음

- fork() 함수가 호출되면 부모프로세스와 거의 동일한 자식 프로세스가 생성.
- fork()를 호출한 후에는 두 프로세스(부모와 자식)이 있으므로, 한 프로세스에서는 else if 블록이 실행되고, 다르 프로세스에서는 else 블록이 실행]
- 따라서 위의 코드를 실행하면 부모 프로세스가 "Hello, child!"라는 메시지를 자식 프로세스로 전달하고, 자식 프로세스는 해당 메시지를 받아 출력
7. unlink
- 파일 시스템에서 파일을 삭제하는데 사용되는 함수로, 해당 파이르이 디렉토리 엔트리를 제거하여 파일을 삭제
- 삭제 성공하면 0, 실패하면 -1.
#include <unistd.h>
int unlink(const char *pathname);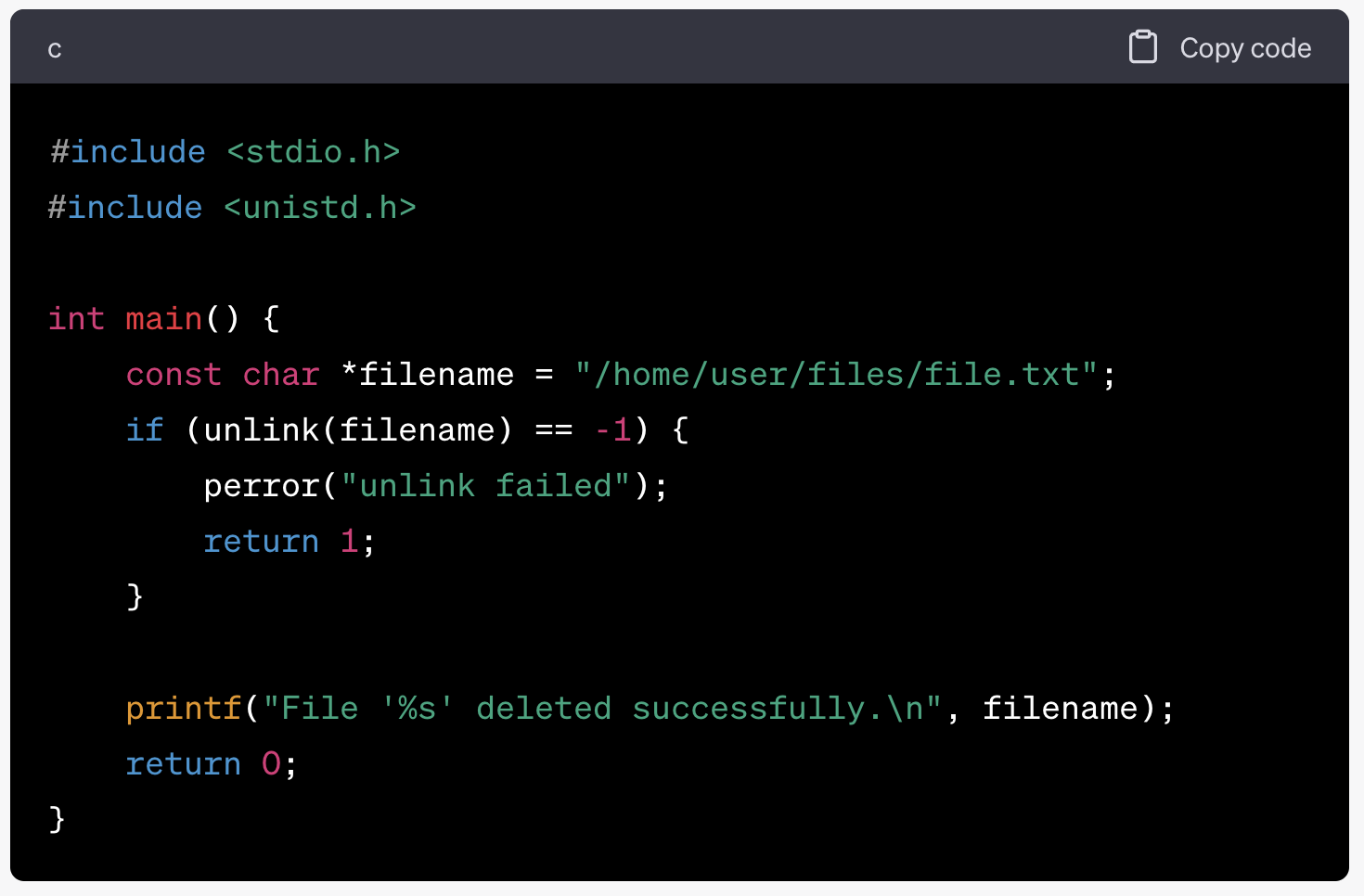
- 상대경로, 절대경로 둘 다 사용할 수 있음
8. wait / waitpid
1) wait
-부모 프로세스가 자식 프로세스가 종료될 때까지 기다리도록 하는 역할
#include <sys/types.h>
pid_t wait(int *status);- status 매개변수를 통해 어떤 방식으로 자식 프로세스가 종료 되었는지를 부모 프로세스가 알 수 있음
- 종료한 자식 프로세스의 프로세스 pid를 반환
* 넘겨주었던 status를 아래와 같은 매크로에 넣어 종료 상태를 확인할 수 있음.
| WIFEXITED(status) | 자식 프로세스가 정상적으로 종료되었는지 확인. 정상 종료되었다면 이 매크로는 참 값을 반환 |
| WEXITSTATUS(status) | 자식 프로세스의 반환 값을 얻기 위해 사용. WIFEXITED(status)가 참일 때만 호출 |
| WIFSIGNALED(status) | 자식 프로세스가 시그널에 의해 종료되었는지 확인하는데 사용 |
| WTERMSIG(status) | 자식 프로세스를 종료시킨 시그널의 번호를 반환. WIFSIGNALED(status)가 참일때만 호출 |
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
pid_t pid = fork();
if (pid == -1) {
perror("fork failed");
return 1;
} else if (pid == 0) {
// This is the child process.
printf("I'm the child process.\n");
exit(7);
} else {
// This is the parent process.
printf("I'm the parent process.\n");
int status;
pid_t child_pid = wait(&status);
if (WIFEXITED(status)) {
printf("Child %d ended normally. Exit status: %d\n", child_pid, WEXITSTATUS(status));
} else {
printf("Child %d ended abnormally.\n", child_pid);
}
}
return 0;
}
2) waitpid
- 자식 프로세스의 상태 변화를 기다리는데 사용되며, wait() 함수보다 더 풍부한 기능을 제공
pid_t waitpid(pid_t pid, int *status, int options);| pid | 대기하려는 자식 프로세스의 ID를 지정 |
pid > 0 | 프로세스 ID가 pid인 자식 프로세스를 기다림 | |
| pid = 0 | 호출자와 같은 프로세스 그룹 ID를 가진 모든 자식 프로세스를 기다림 | |||
| pid = -1 | 모든 자식 프로세스를 기다림 | |||
| pid < -1 | 프로세스 그룹 ID가 pid인 절대 값인 자식 프로세스를 기다림 | |||
| status | 자식 프로세스의 종료 상태를 저장하는 포인터 | |||
| options | 옵션을 설정하는 플래그 | WNOHANG | 상태 변경을 감지할 수 있는 자식 프로세스가 존재하지 않을 경우 즉시 0을 반환 | |
| WUNTRACED | 자식 프로세스가 중지된 경우에도 (일시 정지와 같은 상황) waitpid()를 반환하여 부모 프로세스가 자식 프로세스의 일시 정지 상태를 알 수 있음 | |||
'운영체제' 카테고리의 다른 글
| [가상머신] 파티션, sudo 설정, ufw, ssh, 비밀번호 정책설정, cron (0) | 2023.07.02 |
|---|---|
| 8. 가상 메모리 - 페이징 기법/세그먼테이션 기법 (0) | 2022.06.08 |
| 7. 메모리 관리 기법 - 절대주소와 상대주소/메모리 오버레이와 스왑/가변분할방식과 고정분할방식 (0) | 2022.06.08 |
| 5. 프로세스 동기화 - 프로세스 간 통신/공유자원/임계구역/피터슨&데커 알고리즘 (0) | 2022.06.07 |
| 4. CPU 스케줄링 - 개요/우선순위/종류 (0) | 2022.06.04 |
















